
Incertitude
Projet en cours! Cette section sera complétée au fur et à mesure de l’avancement du projet.
PORTIC repose sur des données historiques sur la navigation et le commerce qui ont alimenté deux bases de données. Le passage des sources manuscrites à de bases de données formalisées a impliqué une série d’opérations et l’ajout d’un nombre certain de champs.
Ces données et métadonnées présentent des caractéristiques qui les rendent « imparfaites » aux yeux des informaticiens. Cette « imperfection » vient de leur caractère d’incertitude, de leurs lacunes, de leur imprécision. Il convient de souligner que les historiens ont l’habitude de travailler avec cette incertitude, inhérente aux traces du passé. Elle peut par ailleurs être signifiante, et inviter l’historien à chercher d’autres traces témoignant des pratiques de l’époque. Ainsi, on pourra s’interroger sur les tonnages changeants de ceux qui sont de toute évidence les mêmes navires : les tonnages semblent systématiquement surestimés dans certains ports et sous-estimés dans d’autres.
Reste que le traitement informatique des données impose la nécessité de formaliser ces incertitudes, lacunes et imprécisions d’une manière cohérente et explicite, afin que les manipulations informatiques d’abord, les visualisations ensuite, puissent les prendre en compte. Dans certains cas, l’incertitude a été tranchée par l’équipe (par ex., quant à la graphie d’un nom propre mal écrit sur le manuscrit). Dès que nous sommes intervenus sur les sources, en les interprétant, une sémiologie spécifique permet de déceler nos interventions sur les données. Ceci facilite, le cas échéant, la correction des erreurs de compréhension ou d’interprétation décelés par les algorithmes de vérification de cohérence que nous avons élaborés.
Une partie considérable du programme PORTIC est consacrée à la visualisation de l’incertitude des données, qui a souvent tendance à « disparaître » lors des visualisations. PORTIC ambitionne rendre compte visuellement des lacunes et des incertitudes qui entourent les données collectées, et de ne pas « gommer » leur caractère imprécis.
Cette section détaille les divers types d’incertitudes que nous avons identifiés et la manière de procéder qui a été la nôtre.
L’incertitude propre aux sources
Les sources mobilisées pour Navigocorpus sont incomplètes, dans la mesure où un certain nombre de registres des congés ne sont plus conservés. La complétude elle-même est par ailleurs incertaine, dans la mesure où pour un certain nombre de lieux nous ne savons pas si les registres ont existé.
Des questions de complétude et d’incertitude se posent également à l’intérieur de chaque registre. Les greffiers ne notaient pas toujours les mêmes informations, en oubliaient certaines parfois, ou se trompaient parfois.
Aussi, ils sont détenteurs de pratiques administratives qu’ils n’ont pas nécessairement pris le temps de consigner à l’écrit, et qu’il faut donc interpréter pour bien pouvoir mobiliser la source, avec le risque de se tromper à notre tour.
Ce document permet de prendre la mesure des défis auxquels nous avons été confrontés.
Sources incomplètes ou redondantes
- Nous connaissons un certain nombre de registres de congés manquants: les comptes-rendus nous permettent de chiffrer le nombre de congés délivrés, à défaut d’en connaître les détails. Nous nous efforceront d’intégrer la présence de ces ports dans les visualisations pour montrer les lacunes du corpus.
- Nous savons que certains ports existaient mais nous n’avons ni les registres, ni les comptes-rendus. C’est le cas, entre autres, pour la plupart des colonies, mais aussi pour Libourne et d’autres ports d’une certaine envergure, à recenser dans la mesure du possible à partir de l’enquête de Chardon dans les années 1780. Mais pour de ports mineurs, nous ne savons pas si les congés étaient pris dans le port à côté.
- Dans le cas de Marseille, les historiens ont eu tendance à croire que les doublons entre les registres de petit cabotage et les dépositions des capitaines à l’arrivée étaient minimes. Or, nous avons constaté qu’ils représentent environ 4% des enregistrements. Une fouille de données soit préciser ce qui est enregistrés par les cahiers seulement, et ce qui donne lieu à un double enregistrement. Reste que les registres du petit cabotage n’étant disponibles qu’à partir de 1786, les données antérieures sous-estiment lourdement la navigation vers Marseille depuis la Méditerranée occidentale.
Incomplétude et imprécisions dans les entrées du registre
Certaines informations sont systématiquement présentes dans certains ports (ex.: le port d’attache) et systématiquement absentes d’autres. Parfois, le greffier a occasionnellement oublié le nom du navire, du capitaine, ou le tonnage, voire la destination. Dans la visualisation des sources disponibles que nous proposons, il est possible de visualiser la part des informations connues sur le total, et la part de celles qui proviennent du travail d’identification des navires que nous avons effectué.
Aussi, nous avons constaté un certain nombre d’imprécisions dans les sources. Certaines sont dues au fait que les greffiers notent de toute évidence ce qu’ils entendent oralement, sans avoir toujours un document écrit sous les yeux. Leurs transcriptions des noms de lieux et des noms de personnes sont d’autant plus aléatoires que le terme sonne étrange à leurs oreilles (noms bretons ou étrangers ; localités étrangères peu fréquentées). Aux Sables-d’Olonne, Aber-Ildut s’appelle « La Berlduque ». Dans certains ports le nom du navire étranger est systématiquement traduit en français, avec des possibles erreurs. Mais c’est surtout la variation des tonnages qui nous a intrigué, et qui a donné lieu à une fouille de données spécifiques.
L’incertitude ontologique : le futur du passé
Par définition, le futur est incertain. Ainsi toute déclaration de destination future renvoie au statut incertain de l’information. Le navire peut avoir fait naufrage, avoir été capturé, avoir essuyé du mauvais temps qui l’oblige à changer de plan.
Nous avons donc indiqué dans un champ dédié (Pointcall_statuts) de Navigocorpus, le statut de l’information relatif à chaque localité fréquentée par le navire par un marqueur (« P » pour le passé, « F » pour le futur ; sur la capture d’écran qui suit, le statut se trouve dans la dernière case à droite du nom du port). Ce statut est relatif au point où le voyage a été observé.
La « certitude » indiquée par la deuxième lettre « C » est donc relative à l’entrée documentaire (l’indication fournie par une sourcé donnée pour un navire donné à une date donnée), et ne doit pas être entendue en sens absolu. Ainsi, si le capitaine déclare aller à Nantes en sortant de Bordeaux, Nantes sera associé à un statut « FC » (« futur certain » : certain donc pour le capitaine à la date de la déclaration). La question de savoir si d’autres sources confirment ou infirment cette déclaration est différente, et elle a été donc traitée séparément dans un autre champ de la base (voir infra, section : incertitude des trajets). « Certain » dans ce contexte n’est donc pas synonyme d’ « avéré », et il faudra que cela soit clair lors de l’interrogation dans les visualisations en ligne. Nous sommes toutefois aussi en mesure de confirmer ou pas que ce navire est effectivement arrivé à Nantes, car nous avons les congés de Nantes. Grâce à un algorithme, les trajets indiqués ont été qualifié, ce qui permet de qualifier le degré de réalisation des intentions futures, ou de laisser planer l’incertitude dès lors que nous ne disposons pas d’informations suffisantes.
Quand l’information de la destination intentionnelle se trouve contredite par la même source qui la déclare (dans le cas, par ex., d’une prise en mer), la deuxième lettre « U » indique l’intention non remplie. Ainsi, le vaisseau La Ville d’Yverdun parti de Marseille le 28 décembre 1787 pour se rendre à Smyrne, rentre à Marseille quatre jours plus tard, après avoir essuyé des dommages aux îles du Frioul. La destination Smyrne est donc associée au statut qui indique une intention passée non avérée, « PU »:
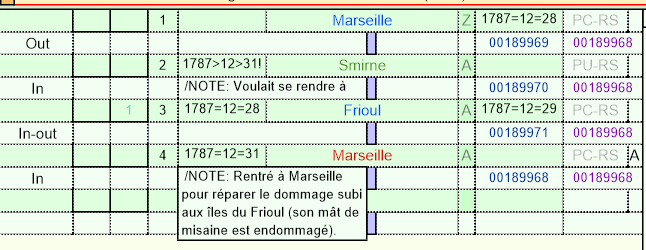
La certitude du voyage avéré se répercute sur l’ensemble des données associées. Ainsi, dans le cas précédent, si la sortie d’un tonnage depuis Bordeaux est certaine car attestée par la source, l’arrivée de ce tonnage (ou de ce capitaine, ou de tel produit chargé à Bordeaux, etc…) est incertaine. Une valeur d’incertitude est donc attribuée à chaque variable pour leur visualisation, pour permettre à l’utilisateur de prendre la mesure de la qualité certaine ou pas de l’information.
Les limites inhérentes à la nature des sources
La législation en vigueur obligeait les capitaines et patrons de barque à prendre un congé. Il y avait, toutefois, des exceptions et des typologies de congés qui compliquent notre travail de reconstitution de la navigation:
- pour un aller-retour au sein de la même amirauté, un seul congé à l’aller suffit. C’est donc l’existence d’un congé suivant pour le même navire et capitaine qui atteste d’un voyage de retour, inexistant dans la base de données Navigocorpus en tant que tel. Si l’existence du voyage peut être ainsi indirectement attestée, ni sa date, ni la cargaison ne sont connues. Il y a donc une sous-estimation systématique des flux de marchandises et de navires, qui peut en partie être signalée. La visualisation des itinéraires de navires « crée » ce voyage retour avec une sémiologie spécifique.
- dans certaines amirautés, il existe de congés d’une durée déterminée. C’est le cas, entre autres, en Bretagne et Normandie, pour des navigations au sein de la province. Les congés de pêche au poisson frais sont en général d’une durée annuelle. Comme les sources ne le précisent pas toujours, nous nous efforcerons de signaler ce type de congés à chaque fois que cela est possible, et de prendre en compte la sous-évaluation qu’ils entrainent dans les mouvements du port.
L'incertitude liée aux identifiants
Comme dans toute base de données, nous avons distingué le niveau de la saisie des données, qui respecte au maximum la source et sa graphie, et celui de l’attribution d’identifiants dans des champs dédiés, qui vise à normaliser les informations. Cette section explique les choix qui ont été faits, le degré d’incertitude qui en découle, et la manière que nous avons choisie pour la traiter ou la représenter.
L’identification des navires
La densité de l’information présente dans la base permet d’envisager de retracer l’itinéraire d’un navire dans le temps, à travers plusieurs sources. Rien, toutefois, dans la source, permet d’attester qu’il s’agit d’un seul et même navire. L’attribution d’un identifinat (ship_id) a été faite manuellement, en prenant en compte la proximité du nom, la similarité du tonnage, la similarité du nom du capitaine, la proximité du port d’attache et toute autre information contextuelle.
Cette identification est, stricto sensu, systématiquement incertaine, et des erreurs d’identification existent, surtout pour les noms très fréquents. Nous allons continuer à les corriger tout au long du programme et par la suite. Un algorithme a été par ailleurs développé par l’équipe (2021) pour permettre de « prédire » la possible que deux ou plusieurs entrées documentaires se réfèrent à un seul et même navire.
L’attribution du pavillon [ship_flag]
Le pavillon est rarement indiqué par les sources utilisées.
La plupart des fois, nous avons déduit le pavillon (indiqué dans la base entre crochets) à partir d’autres variables renseignés, comme le port d’attache du navire ou, à défaut, les indications d’appartenance du capitaine (les navires d’un capitaine de Saint-Tropez ou d’un capitaine ‘catalan’ se voient ainsi attribuer respectivement le pavillon [French] et [Spanish]).
Pour les navires qui ont pris un congé (série G5), une information supplémentaire vient de la nature de celui-ci (congé français, congé étranger), en sachant toutefois que dans certains ports français, les navires espagnols bénéficient d’un traitement de faveur et prennent donc des congés français. L’indication d’un congé français a donné lieu à l’indication de pavillon [French] même en l’absence de tout autre champ pouvant donner des indices quant au pavillon du navire.
L’attribution d’un pavillon indéterminé mais pas français [NonFrench] caractérise tous les navires qui ont payé en France un congé étranger et pour lesquels aucun autre élément dans l’unité documentaire ou dans les unités documentaires relatives au même navire (=même ship_id) ne permet de supposer la nationalité.
L’information entre crochets est qualifiée d’incertaine dans les visualisations [niveau -2].
L’identification des capitaines
Navigocorpus attribue un identifiant de capitaine (captain_id) pour permettre d’en retracer sa navigation dans le temps. L’identification est, stricto sensu, systématiquement incertaine, et des erreurs d’identification existent, surtout pour les noms très fréquents. Nous allons continuer à les corriger tout au long du programme et après.
Pour l’attribution du captain_id, qui a été faite manuellement, nous avons pris en compte la proximité du nom, la fidélité au même navire, la similarité du tonnage de navires et des aires de navigation lorsqu’une même personne semble changer de navire, la proximité du port d’attache et toute autre information contextuelle.
Les cas les plus épineux sont ceux où le capitaine a plusieurs prénoms. Jean Dupont et Pierre Dupont ont deux identifiants différents, même s’ils servent sur le même navire, mais lorsque nous trouvons également un Jean Pierre Dupont sur le même navire, on a penché plutôt pour l’attribution d’un seul et même identifiant aux trois toponymes. Reste que l’utilisateur doit être averti que la transcription des noms propres et l’identification des capitaines est en soit sujette à caution. Pour faciliter la recherche des navires et des capitaines par leur nom, la visualisation de leurs trajectoires propose une recherche avec toutes les variantes orthographiques présentes dans la base de données.
L’identification des produits
texte en cours de rédaction.
L'identification des lieux
Les sources mobilisées présentent les indications de lieux suivantes, qui ont été pourvue d’un identifiant (UHGS). Par « localité » il faut entendre un port, une aire géographique (« mer Baltique »), un point en mer (« 20 lieus à l’ouest de Malte »), un pays (« Angleterre »), une région (« Catalogne »), ou encore une appartenance géographique-culturelle-religieuse (« grec », à une époque où la Grèce n’est pas un Etat indépendant):
- Localité d’où le navire part/arrive
- Localité où le navire va/où il a été
- Le port d’attache du navire
- Le lieu d’appartenance du capitaine (captain_brithplace)
- L’indication d’appartenance culturelle-politique du capitaine (captain_birthplace)
Si l’identification de la plupart des indications de lieu ne pose pas de problème, l’incertitude plane sur certaines localités. Plusieurs localités n’existent en effet pas/plus sous la dénomination utilisée par la source les désigne.
Une connaissance experte qui tranche. La connaissance experte a permis d’identifier des localités dont le nom a changé dans le temps (Aligre = Marans ; Frederikfiord = Flekkefjord) ou lorsqu’il désigne le quartier portuaire d’un bourg (Riberou = Saujon). Dans ce cas, on a laissé le terme indiqué dans la source et attribué le code correspondant à la localité actuelle.
Une interprétation plausible. Nous avons aussi pris la responsabilité d’un certain nombre d’interprétations. Ainsi, nous pensons que « Calvezé » ou « Calzesé en Corse » correspond à Cargèse et nous avons donc attribué à ces deux toponymes un identifiant UHGS correspondant à Cargèse.
Localités homonymes. Les sources fournissent parfois le nom d’un lieu parfaitement connu, mais qu’il est délicat d’identifier en raison de l’existence d’homonymes. La connaissance experte nous a menés à réduire le nombre de cas incertains. Voici quelques exemples d’homonymies sur lesquelles nous avons tranché dans un sens ou dans l’autre :
- Talmont : l’expertise locale de l’équipe a permis de déterminer qu’il ne s’agit pas de Talmont-sur-Gironde, mais de Talmont-Saint-Hilaire, appelé dans nos sources aussi Tallemon d’Aulonne.
- De toute évidence, « Romagne » ne désigne pas l’actuelle région italienne dont Bologne est le chef-lieu, mais est un attribut signifiant « de la région de Rome » : ainsi Fiumicino, Terracine (ou Terrassino), Corneto [ancien nom de Tarquinia] sont parfois définis comme « de Romagne ».
- Dans le cas de « Rogobruno » et « Roquebrune », pour des caboteurs arrivant à Marseille : Le registre ne fournit ni le tonnage ni le nombre d’équipage, ni la date de départ depuis ces ports. Notre interprétation est que « Rogobruno » désigne Roquebrune, à côté de Monaco et que « Roquebrune » désigne Roquebrune-sur-Argens. L’interprétation repose sur la langue, Rogobruno faisant alors partie de la principauté de Monaco, donc une localité où l’on parle italien, alors que Roquebrune [sur Argens] est un port français et que le registre est tenu en français.
- « Argentiere » a été interprété comme Kimolos, proche de Milo, appelé autrefois Argentière [voir Anne Mezin [1997] : « consulat de Milo et Argentière »] pour les navires arrivés du Levant, au vu de l’itinéraire et des dates ; et comme Argentiera (en Sardaigne) pour les navires du petit cabotage de Marseille, dans la mesure où ils n’ont pas été inscrits dans les registres de la Santé dédiés aux navires en provenance du Levant.
- Ile Rousse (en Corse ou en Sardaigne) : quand l’appartenance n’était pas explicitement mentionnée par la source, on a attribué le code de la Corse à tout capitaine corse en provenance de l’île Rousse (mais on a aussi de patrons corses qui arrivent à Marseille depuis l’Ile Rousse en Sardaigne) ; sinon, on a regardé l’itinéraire déclaré ou encore d’autres voyages du même capitaine/navire, pour trancher.
- Tossa en Catalogne ou « Tossa en Sicile » [Tusa] : quand l’appartenance n’était pas explicitement mentionnée par la source, on a attribué le code en fonction de la nationalité du capitaine et/ou de la nature de la cargaison.
- Saint Nazaire : sur l’embouchure de la Loire ou Sanary en Méditerranée (anciennement Saint Nazaire) : décision prise en fonction de l’itinéraire et du tonnage du navire, si connu.
- Saint-Valery : si nous retrouvons le navire destiné à « Saint-Valery » par la suite à Saint-Valery-sur-Somme [ou en Caux], nous avons considéré que le « Saint-Valery » en question était celui où nous retrouvons le navire. Lorsque dans d’autres congés le même navire s’était rendu clairement à l’un de deux Saint-Valery, nous avons considéré qu’il s’y rendait dans le même port dans le cas d’un congé qui ne le précise pas. Lorsque le port d’attache d’un navire est Saint-Valery-sur-Somme [ou en Caux], nous avons considéré que sa destination déclarée imprécise [Saint-Valery] coïncidait avec celle de son port d’attache. Les cas résiduels, pour lesquels il est impossible de se prononcer, ont reçu un code spécifique (A1964301) désignant « Saint-Valery-en-Caux ou Saint-Valery-sur-Somme, qui a été géolocalisé entre les deux (963589,1.147613). La création de ce point artificiel a été faite pour Saint-Valery uniquement, le nombre d’occurrences des autres cas indéterminés (ex. : Kerbel) étant très faible, nous avons préféré avoir recours plutôt au code générique d’incertitude H4444444.
Les variables déduites
L’identification des navires ou des capitaines entraîne de notre part le report des variables manquantes sur les autres entrées relatives au même navire ou au même capitaine: par ex. si un document précise le tonnage, nous rapportons celui-ci entre crochets sur les autres entrées du « même » navire. Certains éléments permettent également de déduire le contenu d’une autre variable, qui sera indiqué également entre crochet, comme toute information qui n’est pas fournie par la source elle même qui a donné lieu à l’entrée. Nous précisons ici les critères que nous avons appliqués.
L'attribution du pavillon
Le pavillon est rarement indiqué par les sources utilisées. Dans ce cas, il figure, en anglais, dans le champ « flag », sans crochets. Nous nous sommes servi d’autres variables, lorsqu’elles sont renseignées, pour attribuer [entre crochets] le pavillon que nous estimons être celui sous lequel le navire navigue.
Une partie des congés indiquent le port d’attache du navire. Celui-ci a été utilisé pour déduire le pavillon. Ainsi, un navire de Stockholm se voit attribuer le pavillon (variable: ship_flag) « [swedish]. L’attribution du pavillon a été donc faite en prenant en considération la souveraineté dans les ports indiqués comme port d’attache à l’époque donnée, hormis dans les cas où le document indique expressément que le navire navigue sous un autre pavillon (ex. : navire génois « naviguant sous le pavillon de Jérusalem » ; navire du Rhode Island « naviguant sous pavillon anglais » ; navire de Hambourg ou de Lübeck « naviguant sous pavillon impérial »). L’absence de crochet dans l’attribution du pavillon et le texte dans le champ « remarks » précisent alors le contenu de la source.
Le type de congé fournit aussi indirectement une information sur le pavillon, car la série « congés français » est à priori réservée aux navires français (nous avons constaté quelques exceptions et quelques erreurs probables); en absence d’autres précisions permettant d’affiner, la délivrance d’un congé de la série « congés étrangers » a donné lieu à une indication de pavillon = [NonFrench].
A défaut du port d’attache, les sources marseillaises et quelques registres de congés indiquent une localité ou une attribution géographique rattachée au capitaine : Un Tel d’Antibes [variable: captain_birthplace], Un TelAutre « catalan » [variable: captain_citizenship]. Ces indications ont été utilisées également comme des proxys pour le pavillon, dans la mesure où la législation de l’époque impose que le capitaine soit sujet de l’Etat qui délivre le pavillon.
L’attribution de la souveraineté n’a pas posé de problèmes insurmontables dès lors que le port d’attache ou une attribution géographique du capitaine étaient indiqués par les sources. Il convient juste de préciser les cas les plus délicats, qui concernent les capitaines « grecs » sans autre indication permettant de savoir s’il s’agit d’un navire d’un port d’attache sous domination vénitienne ou sous domination ottomane nous leur avons attribué un code « Greek » géolocalisé sur la Grèce actuelle, mais nous n’avons pas tranché quant aux pavillons.
La qualification de l'incertitude
Nous avons attribué à toute information contenue dans les sources et aux identifiants que nous avons ajoutés une valeur qui qualifie le degré d’incertitude de l’information en question. Ces valeurs sont:
– -4 : information manquante
– -3 : faux, car démenti par autre document ou par une analyse historique
– -2 : le contenu du champ est incertain car dérivé/déduit d’une autre source ou d’une information contextuelle
– -1 : non confirmé (statut de l’information relative à un événement futur non confirmé – pointcall_status = FC)
– 0 : Observé comme du présent ou du passé par la source (pointcall_status = PC)
Un exemple de niveau -3: Un congé est délivré le 1er janvier 1787 dans le port de Bordeaux à un navire appelé la Belle Poule capitaine Jean Durand pour aller à Saint-Domingue. Un autre congé est délivré dans le port de La Rochelle le 21 janvier 1787 à un navire appelé la Belle Poule capitaine Jean Durand pour aller au Cap-Français. Les deux navires ont le même port d’attache et un tonnage très proche. Nous pensons qu’il s’agit du même navire et nous lui attribuons donc le même identifiant de navire (ship_id). En reconstruisant les itinéraires, nous qualifions de « faux » le trajet Bordeaux-> Saint-Domingue et nous proposons avec une sémiologie spécifique ce que nous pensons être le « vrai » trajet: Bordeaux -> La Rochelle -> Cap-Français. Nous avons une certitude (valeur incertitude = 0) pour la sortie de Bordeaux et la sortie de La Rochelle. Nous qualifions la destination Saint-Domingue depuis Bordeaux de -3 (faux, car démenti par autre document ou par une analyse historique); et nous qualifions de -1 l’arrivée à Cap-Français.
Un exemple de niveau -2: nous attribuons à un navire ayant Le Havre comme port d’attache et prenant un congé français, le pavillon = French. Cette information ne se trouve pas dans la source. Elle est donc -2 car incertain/déduit d’une information contextuelle. Autre exemple: une entrée documentaire indique que La Belle Poule a comme port d’attache Le Havre. Nous attribuons Le Havre comme port d’attache à tous les navires auxquels nous avons attribué le même identifiant de navire (ship_id). Le port d’attache de ces entrées documentaires est qualifié -2: incertain car dérivé d’une autre source.